Cross-Modal Dataset Construction
(a) The process of constructing the image captions. (b) Examples of cross-modal images, labels, and prepared captions.
Workflow
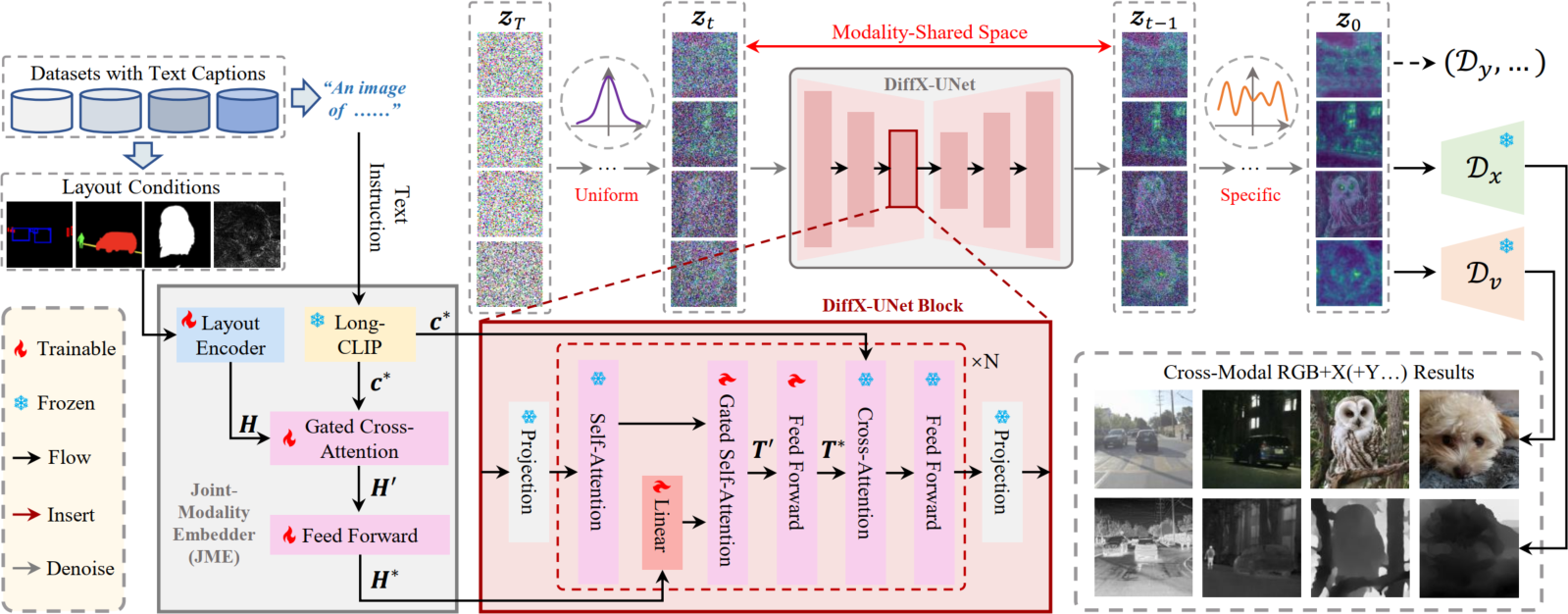
Workflow of our Multi-Path Variational AutoEncoder (MP-VAE). Here, the RGB+X modal encoding is employed for illustration. However, the framework is capable
of supporting additional modal inputs and outputs.
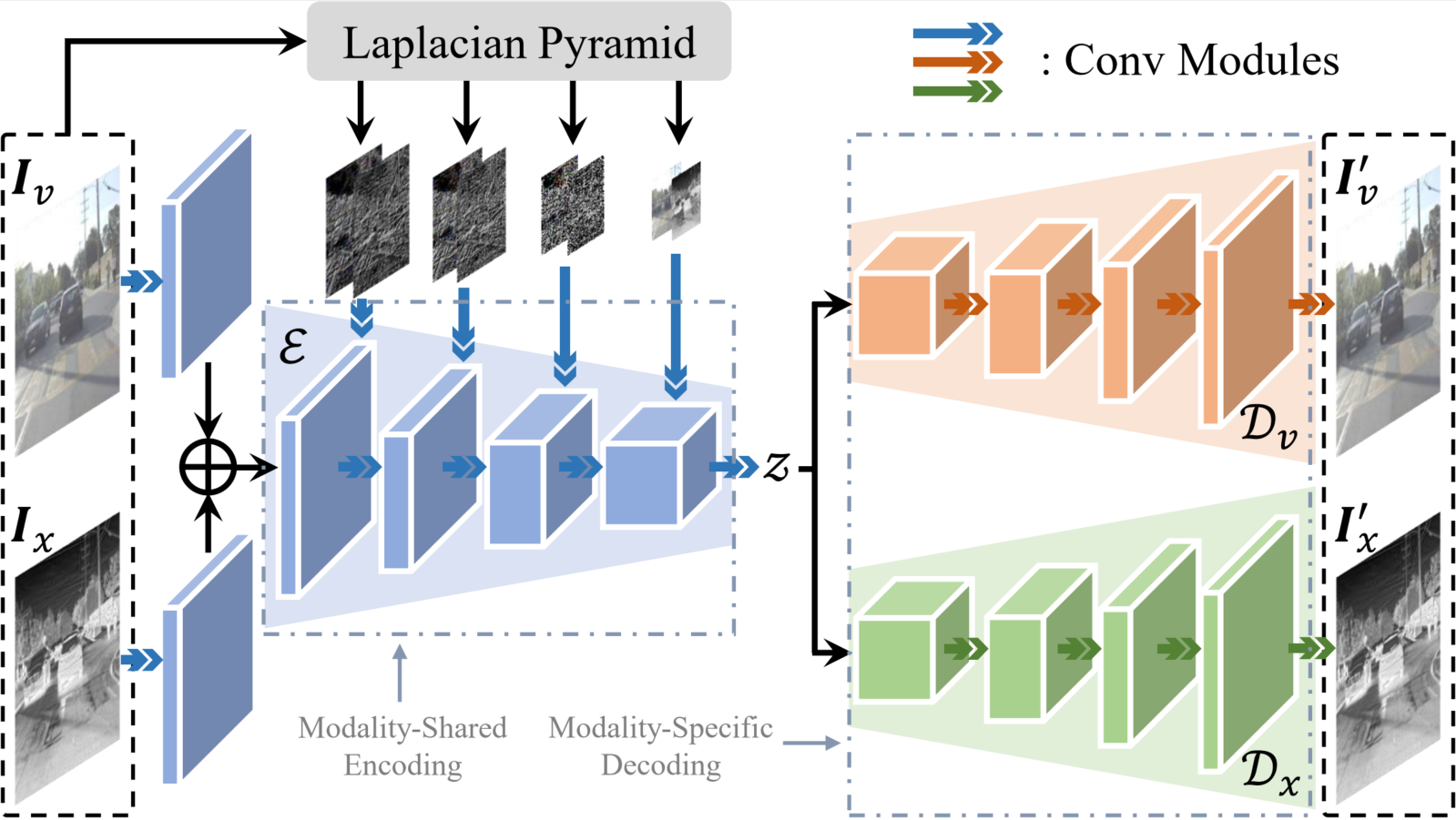
MP-VAE
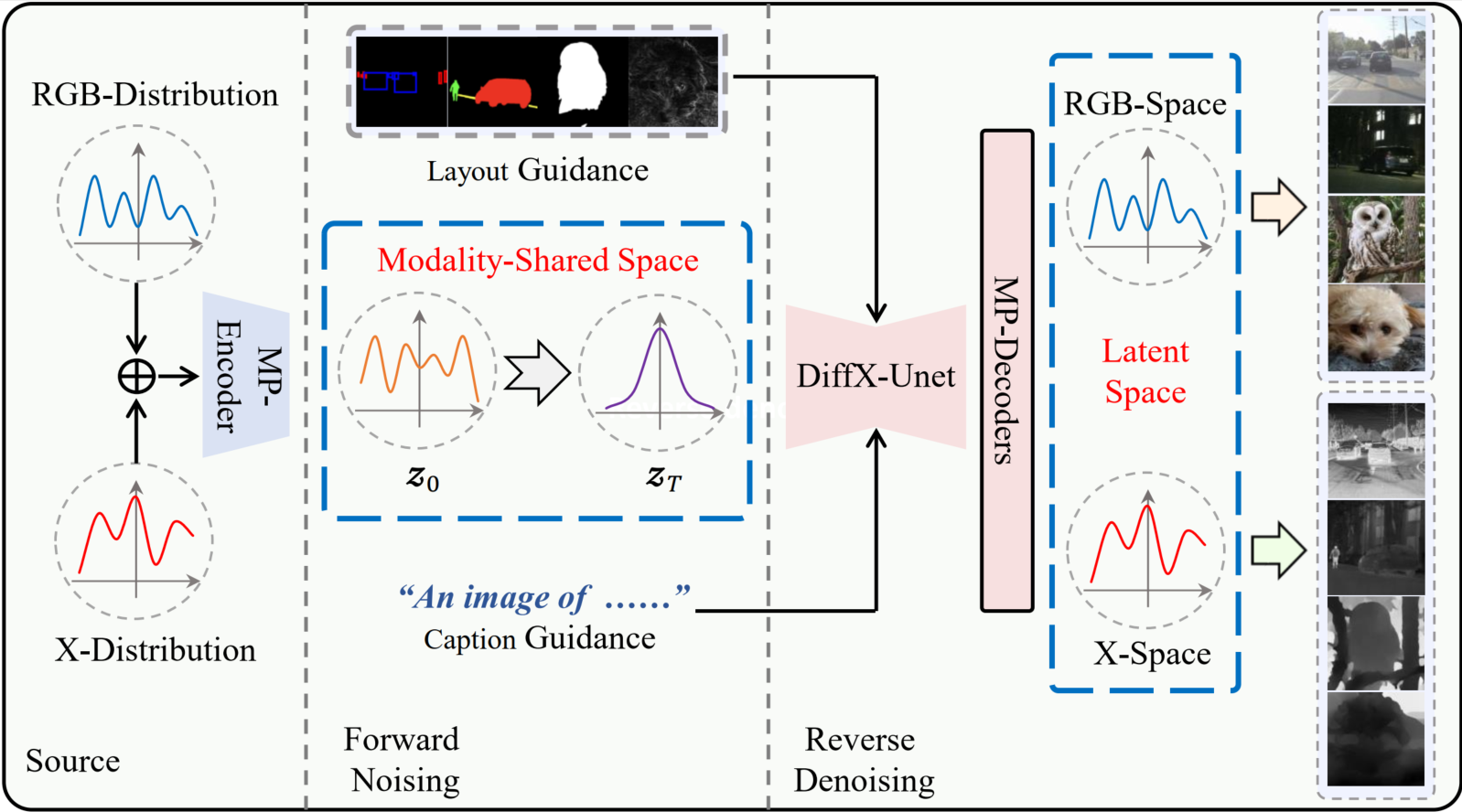
Workflow in Latent Space
Methodology
Diffusion models have made significant strides in language-driven and layout-driven image generation.
However, most diffusion models are limited to visible RGB image generation.
In fact, human perception of the world is enriched by diverse viewpoints, such as chromatic contrast, thermal illumination, and depth information.
In this paper, we introduce a novel diffusion model for general layout-guided cross-modal generation, called DiffX.
Notably, our DiffX presents a simple yet effective cross-modal generative modeling pipeline, which conducts diffusion and denoising processes in the modality-shared latent space.
Moreover, we introduce the Joint-Modality Embedder (JME) to enhance the interaction between layout and text conditions by incorporating a gated attention mechanism.
To facilitate the user-instructed training, we construct the cross-modal image datasets with detailed text captions by the Large-Multimodal Model (LMM) and our human-in-the-loop refinement.
Through extensive experiments, our DiffX demonstrates robustness in cross-modal ``RGB+X'' image generation on FLIR, MFNet, and COME15K datasets, guided by various layout conditions.
It also shows the potential for the adaptive generation of ``RGB+X+Y(+Z)'' images or more diverse modalities on COME15K and MCXFace datasets.
Comparisons
As shown in the figure below, we can see that our DiffX significantly outperforms the baseline methods in qualitative results. It proves the
effectiveness of employing Long-CLIP for caption embedding and our JME for joint-modal connection.
And results in the table below demonstrate that our DiffX outperforms all baseline models in all metrics.

Qualitative Comparison
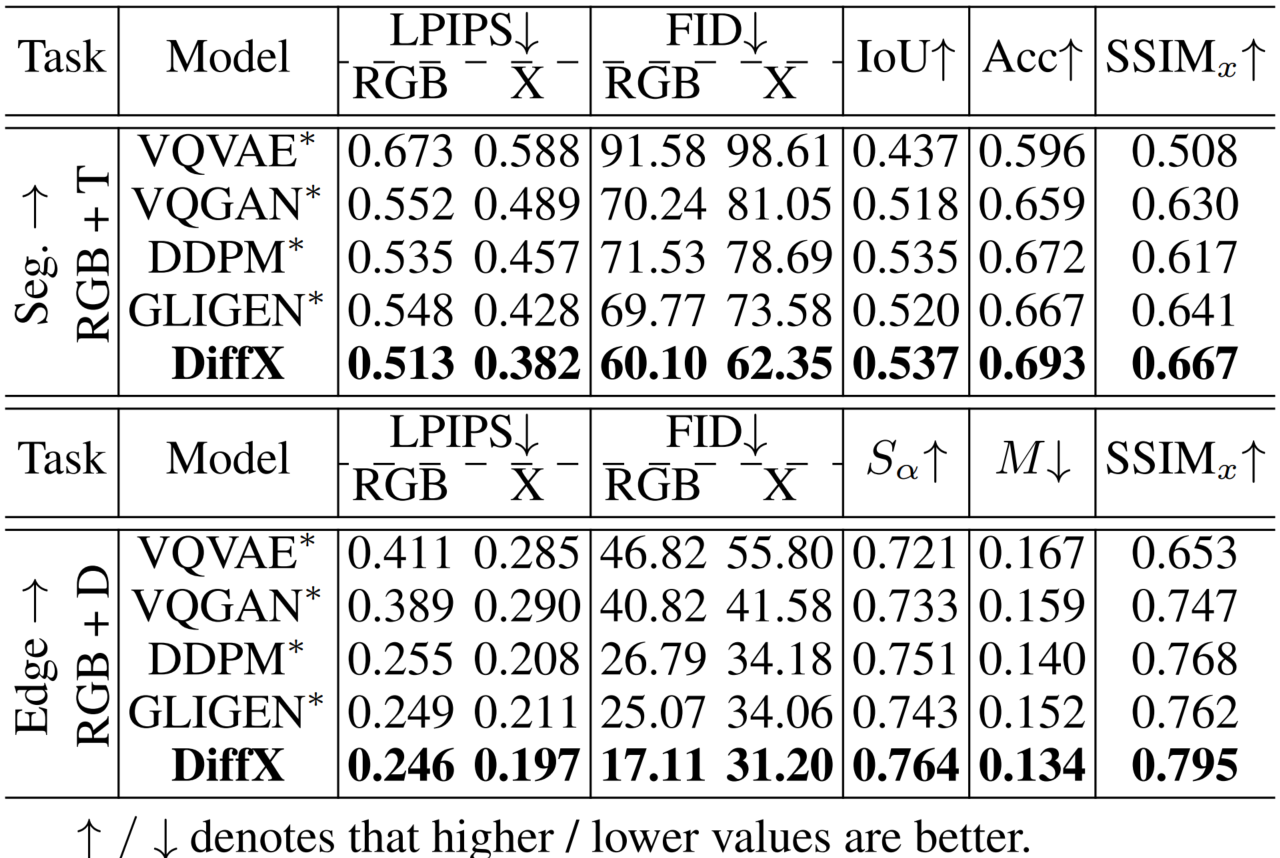
Quantitative Comparison
Analysis
The ablation studies and potential applications are presented here.
Ablation Study
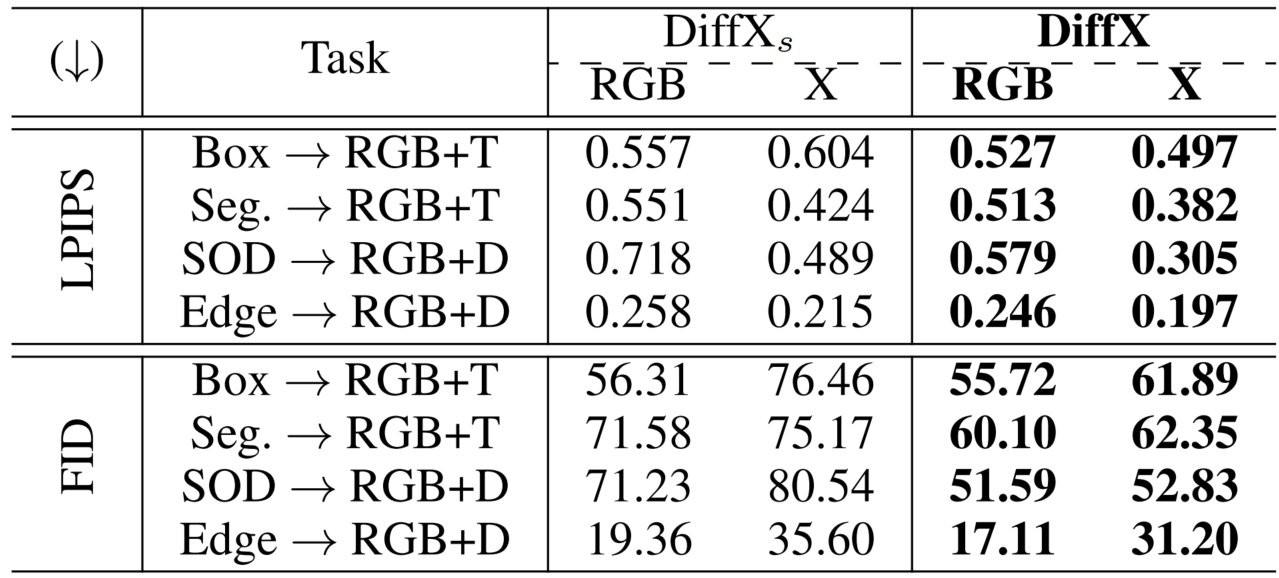
Firstly, we conduct the ablation study on the Laplacian Pyramid (LP) in our MP-VAE. Secondly, we aim to compare the unique-modal generation with the cross-modal RGB+X generation by DiffX.
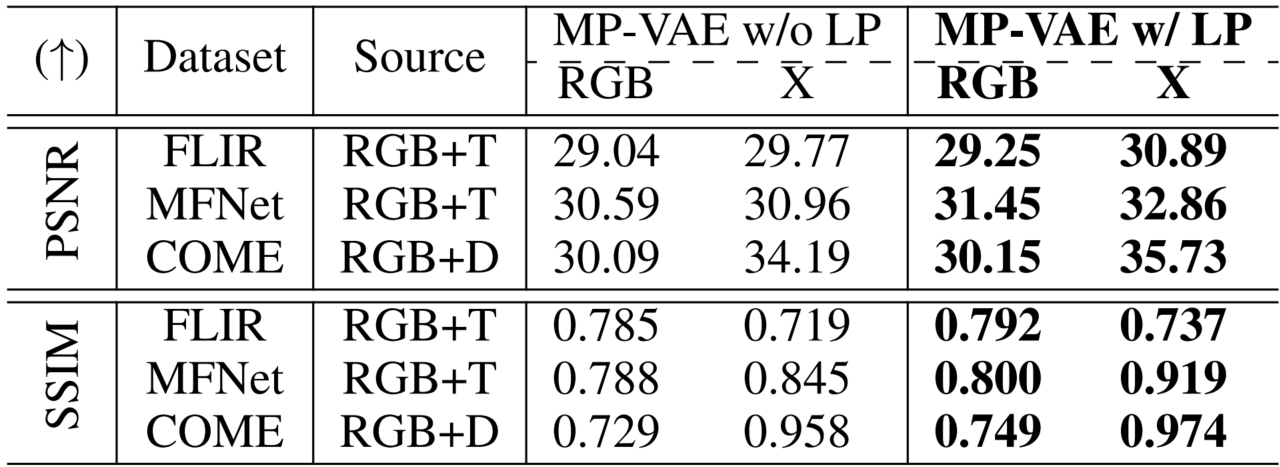
Ablation study on the Laplacian Pyramid
Comparison between the unique- and cross-modal
Effectiveness of long text captions
We conduct the ablation study on the impact of text captions on SOD → RGB+D and Seg. → RGB+T tasks. The qualitative comparison in figure below shows that DiffX can effectively capture the crucial captions, while the variant model without caption embeddings generates broken or misaligned images, ultimately affecting the image quality.

Impact of text captions in cross-modal generation
Adaptation to Diverse-Modal Generation
Given that DiffX’s can generate cross-modal “RGB+X” images, we also wonder if we can apply this framework to robust, controllable, and versatile generation across diverse modalities?
Therefore, we also conduct experiments on COME15K and MCXFace datasets for “SOD → RGB+D+Edge” and “3DDFA → RGB+NIR+SWIR+T”, respectively.
The qualitative results are shown in the figures below, respectively.

Adaptation to “SOD→RGB+D+Edge”

Adaptation to “3DDFA→RGB+NIR+SWIR+T”
Gallery
More results generated by our method are shown here.

“SOD → RGB+D+Edge” task

“3DDFA → RGB+NIR+SWIR+T” task